Water's Home
Just another Life Style
Home
Tags
Categories
Archives
0%
R语言教程-Java、实例
Posted on
2023-08-06
In
multiple-programming-languages
,
R
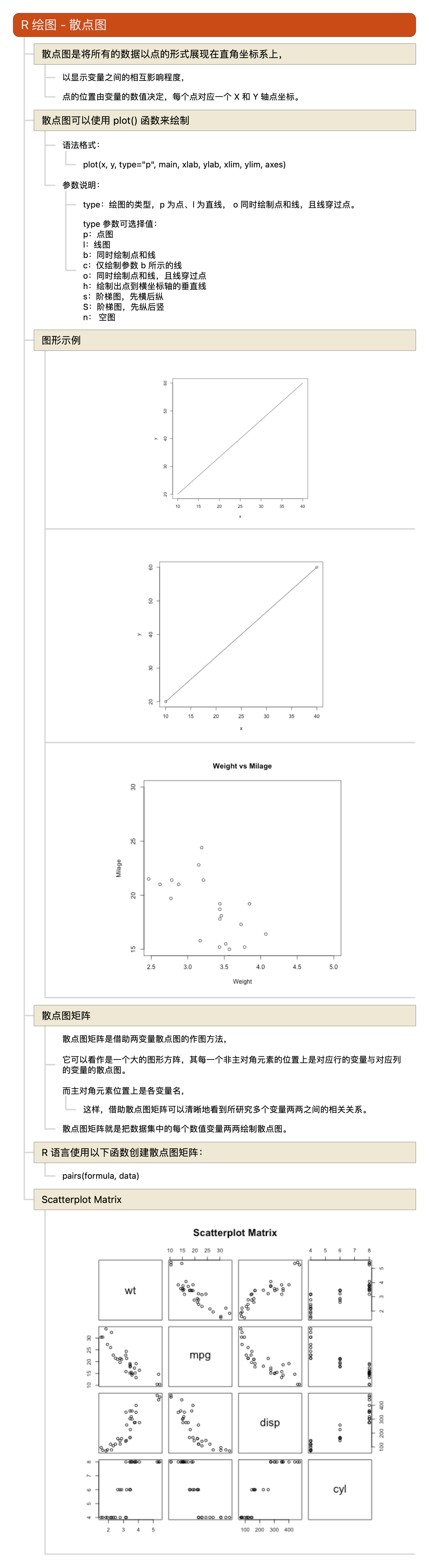
R语言教程-散点图
Posted on
2023-08-06
In
multiple-programming-languages
,
R
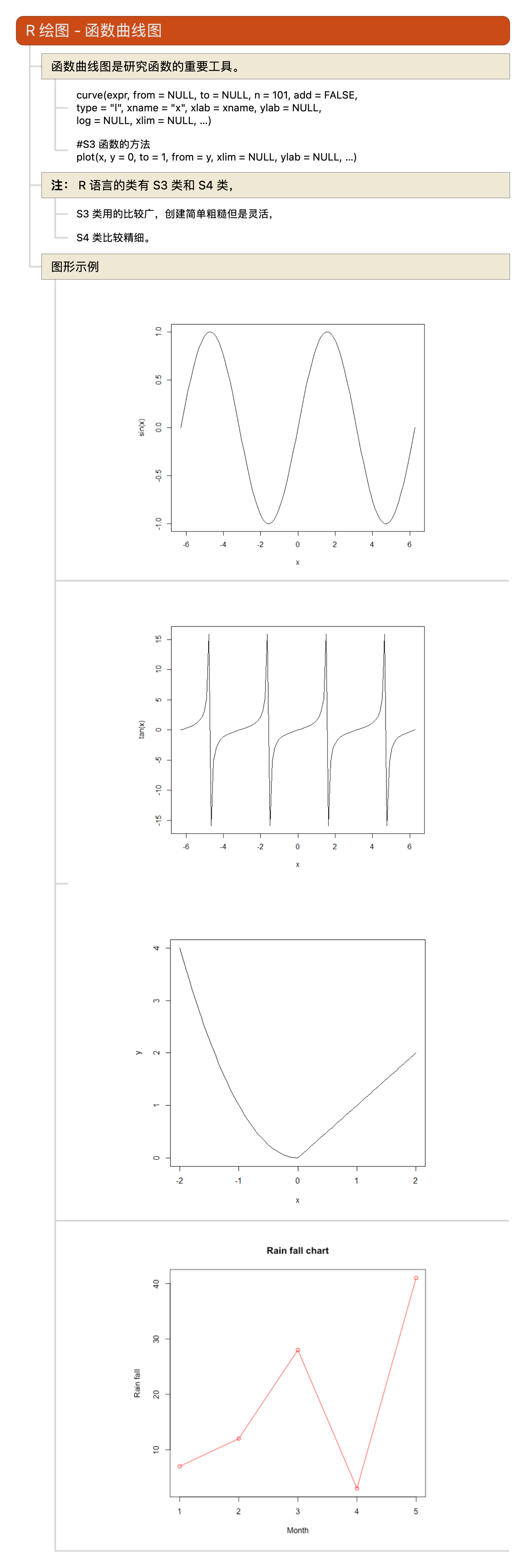
R语言教程-函数曲线图
Posted on
2023-08-06
In
multiple-programming-languages
,
R
R语言教程-中文支持
Posted on
2023-08-06
In
multiple-programming-languages
,
R
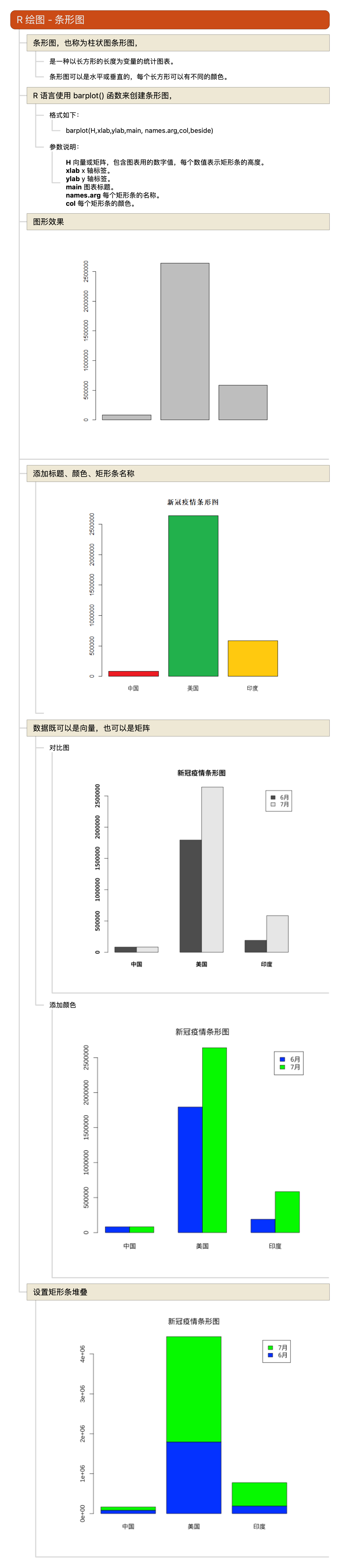
R语言教程-条形图
Posted on
2023-08-06
In
multiple-programming-languages
,
R
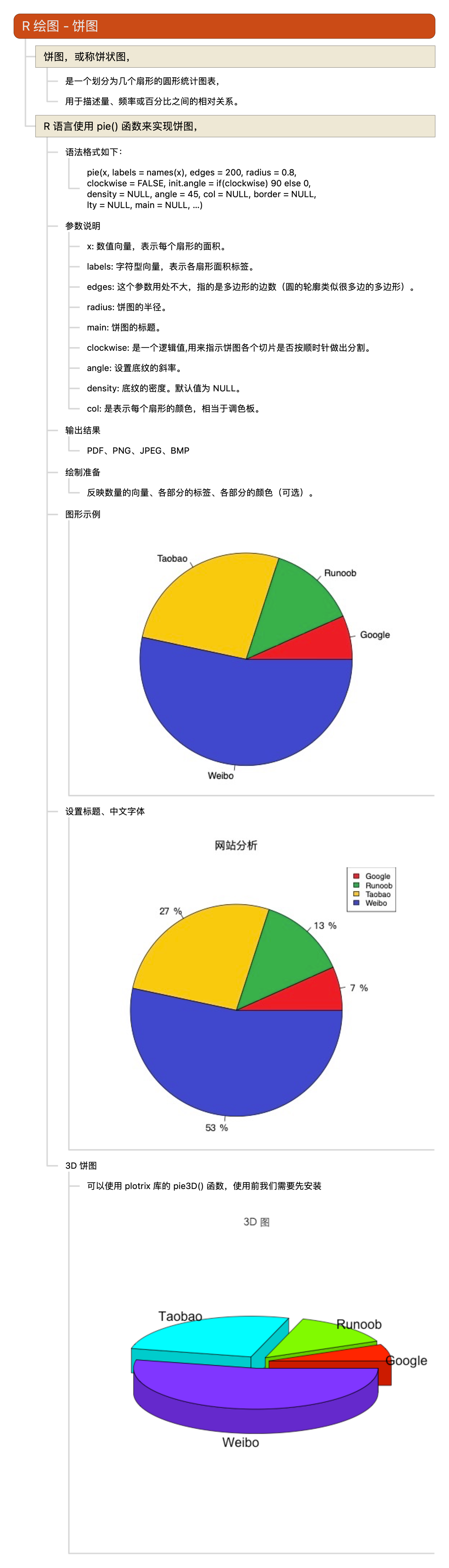
R语言教程-饼图
Posted on
2023-08-06
In
multiple-programming-languages
,
R
R语言教程-CSV、Excel、XML、JSON、MYSQL
Posted on
2023-08-06
In
multiple-programming-languages
,
R
R语言教程-包
Posted on
2023-08-06
In
multiple-programming-languages
,
R
R语言教程-数据重塑
Posted on
2023-08-06
In
multiple-programming-languages
,
R
R语言教程-数据框
Posted on
2023-08-06
In
multiple-programming-languages
,
R
1
2
…
24