Various sequence to sequence architectures
Sequence to sequence models which are useful for everything from machine translation to speech recognition.
- translate
- image captioning
Picking the most likely sentence

Beam Search
You don’t want to output a random English translation, you want to output the best and the most likely English translation. Beam search is the most widely used algorithm to do this. So, whereas greedy search will pick only the one most likely words and move on, Beam Search instead can consider multiple alternatives. So, the Beam Search algorithm has a parameter called B, which is called the beam width. Notice that what we ultimately care about in this second step would be to find the pair of the first and second words that is most likely. so it’s not just a second where is most likely but the pair of the first and second words most likely. Evaluate all of these 30000 options according to the probability of the first and second words and then pick the top three. Because of beam width is equal to three, every step you instantiate three copies of the network to evaluate these partial sentence fragments and the output. And it’s because of beam width is equal to three that you have three copies of the network with different choices for the first words, Beam search will usually find a much better output sentence than greedy search.
Refinements to Beam Search
Length normalization is a small change to the beam search algorithm that can help you get much better results. Numerical underflow. Meaning that it’s too small for the floating part representation in your computer to store accurately. So in most implementations, you keep track of the sum of logs of the probabilities rather than the production of probabilities. Instead of using this as the objective you’re trying to maximize, one thing you could do is normalize this by the number of words in your translation. And so this takes the average of the log of the probability of each word. And this significantly reduces the penalty for outputting longer translations. And in practice, as a heuristic instead of dividing by Ty, by the number of words in the output sentence, sometimes you use a softer approach. We have Ty to the power of alpha, where maybe alpha is equal to 0.7. So if alpha was equal to 1, then yeah, completely normalizing by length. If alpha was equal to 0, then, well, Ty to the 0 would be 1, then you’re just not normalizing at all. And this is somewhat in between full normalization and no normalization. And alpha’s another hyper parameter of algorithm that you can tune to try to get the best results. Pick the one that achieves the highest value on this normalized log probability objective. Sometimes it’s called a normalized log likelihood objective. In production systems, it’s not uncommon to see a beam width maybe around 10. Exact search algorithms :
- BFS, Breadth First Search
- DFS, Depth First Search
Beam search runs much faster but does not guarantee to find the exact maximum for this arg max that you would like to find.
Error analysis in beam search
Beam search is an approximate search algorithm, also called a heuristic search algorithm. How error analysis interacts with beam search and how you can figure out whether it is the beam search algorithm that’s causing problems and worth spending time on. Or whether it might be your RNN model that is causing problems and worth spending time on. Model :
- RNN model (neural network model or sequence to sequence model)
- It’s really an encoder and a decoder.
- P(yx)
- Beam search algorithm
[latex]\left\{\begin{matrix} P(y^{*}x) & use \ model\\ P(\hat yx) & use \ RNN \end{matrix}\right.[/latex] 
Bleu Score
How to evaluate a machine translation system
The way this is done conventionally is through something called the BLEU score.
What the BLEU score does is given a machine generated translation, it allows you to automatically compute a score that measures how good is that machine translation. BLEU, by the way, stands for bilingual evaluation understudy. Tthe intuition behind the BLEU score is we’re going to look at the machine generated output and see if the types of words it generates appear in at least one of the human generated references.  The reason the BLEU score was revolutionary for machine translation was because this gave a pretty good, by no means perfect, but pretty good single real number evaluation metric. And so that accelerated the progress of the entire field of machine translation. Today, BLEU score is used to evaluate many systems that generate text, such as machine translation systems, as well as the example I showed briefly earlier of image captioning systems.
The reason the BLEU score was revolutionary for machine translation was because this gave a pretty good, by no means perfect, but pretty good single real number evaluation metric. And so that accelerated the progress of the entire field of machine translation. Today, BLEU score is used to evaluate many systems that generate text, such as machine translation systems, as well as the example I showed briefly earlier of image captioning systems.
Attention Model Intuition
Attention Model, that makes RNN work much better.
- It’s just difficult to get in your network to memorize a super long sentence.
- But with an Attention Model, machine translation systems performance can look like this, because by working one part of the sentence at a time,
- What the Attention Model would be computing is a set of attention weights.
Attention Model
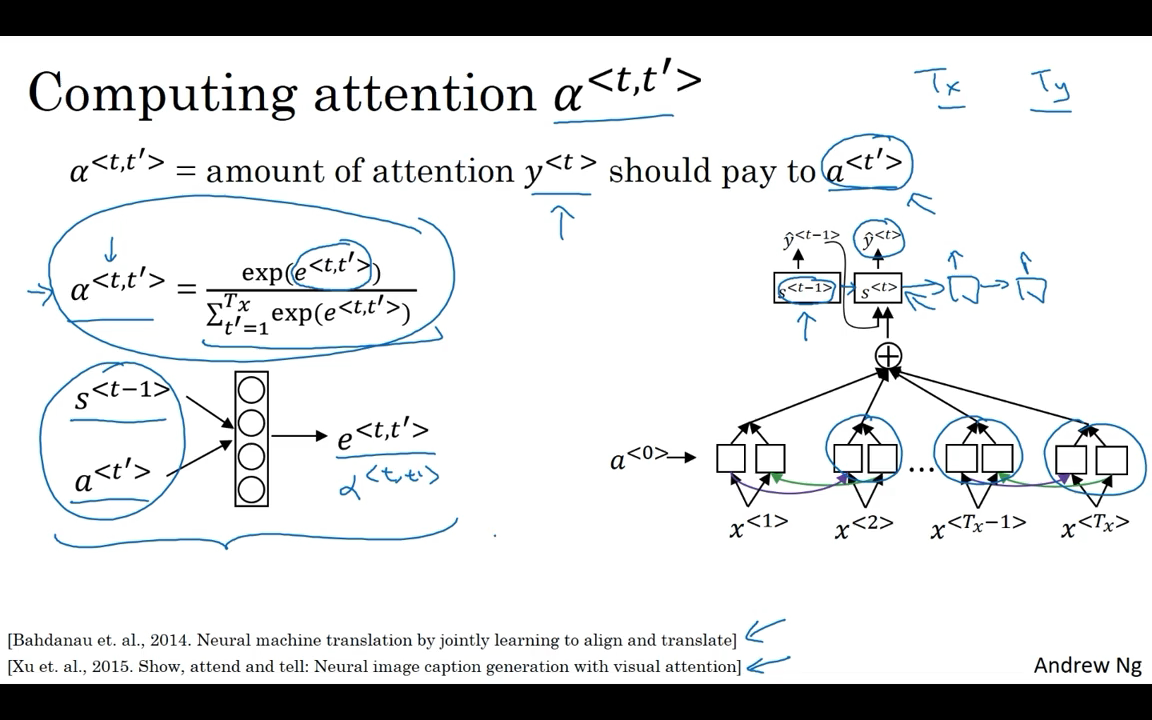 This algorithm runs in quadratic cost, Although in machine translation applications where neither input nor output sentences is usually that long maybe quadratic cost is actually acceptable.
This algorithm runs in quadratic cost, Although in machine translation applications where neither input nor output sentences is usually that long maybe quadratic cost is actually acceptable.
Speech recognition
One of the most exciting developments were sequence-to-sequence models has been the rise of very accurate speech recognition. A common pre-processing step for audio data is to run your raw audio clip and generate a spectrogram. So, this is the plots where the horizontal axis is time, and the vertical axis is frequencies, and intensity of different colors shows the amount of energy. Once upon a time, speech recognition systems used to be built using phonemes and this where, hand-engineered basic units of cells. But with end-to-end deep learning, we’re finding that phonemes representations are no longer necessary. 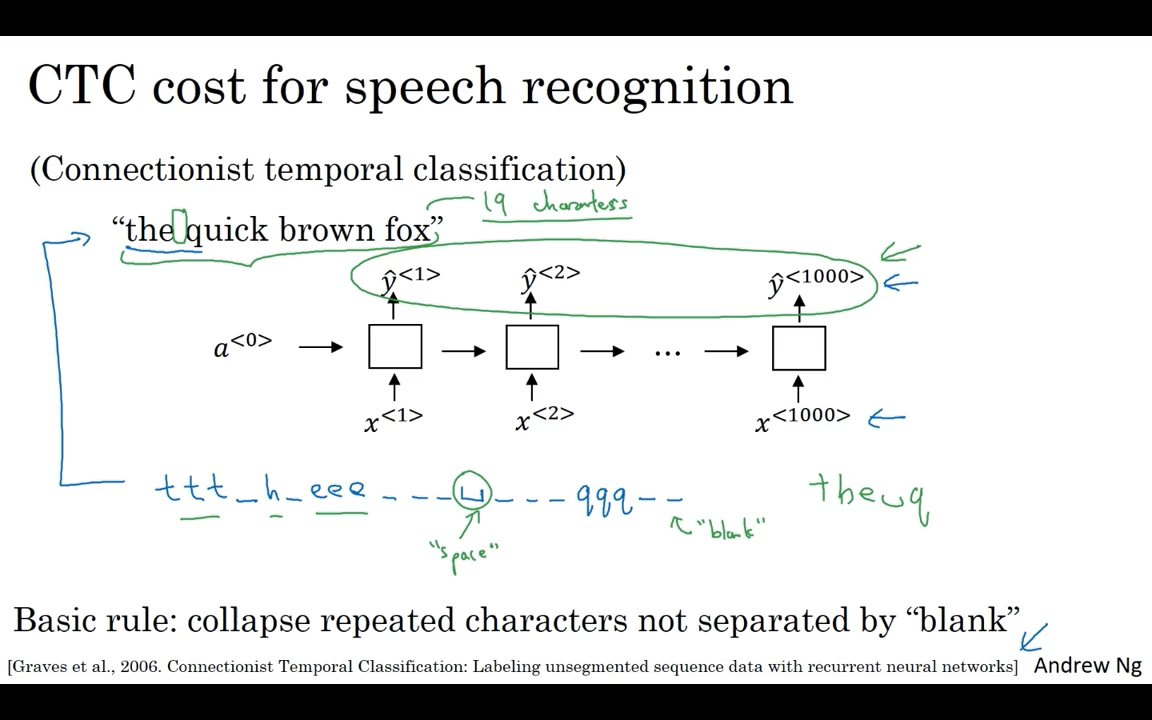
Trigger Word Detection
When the rise of speech recognition have been more and more devices you can wake up with your voice and those are sometimes called trigger word detection systems. 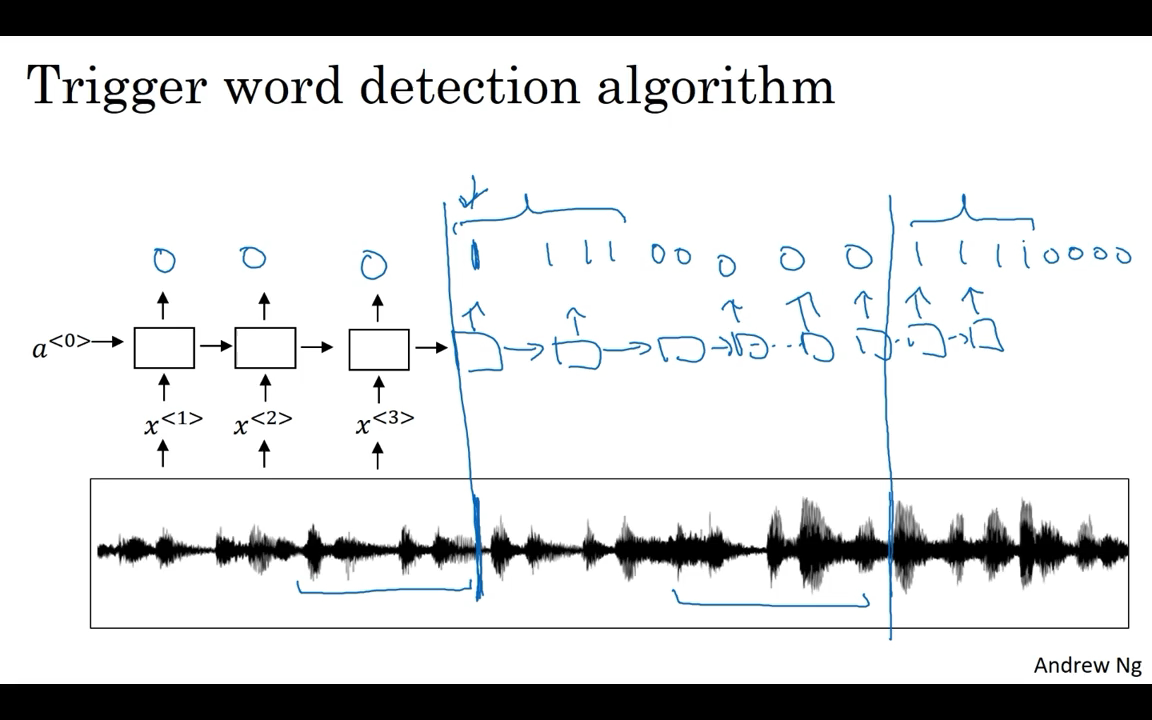 Then in the training sets you can set the target labels to be zero for everything before that point and right after that to set the target label of one.And then if a little bit later on the trigger word was said again, and the trigger was said at this point, then you can again set the target label to be one right after that.
Then in the training sets you can set the target labels to be zero for everything before that point and right after that to set the target label of one.And then if a little bit later on the trigger word was said again, and the trigger was said at this point, then you can again set the target label to be one right after that.
One slight disadvantage of this is it creates a very imbalanced training set.So a lot more zeros than ones.
Instead of setting only a single time step to output one, you can actually make an output a few ones for several times or for a fixed period of time before reverting back to zero. So and that, slightly evens out the ratio of ones to zeros. But this is a little bit of a hack.