Why Sequence Models?
Models like recurrent neural networks or RNNs have transformed speech recognition, natural language processing and other areas. 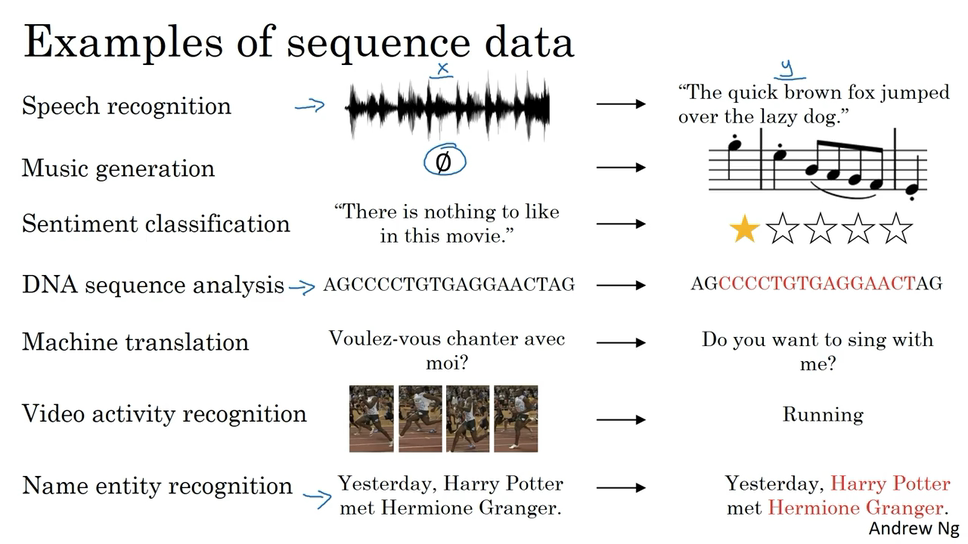
Notation
Suppose the input is the sequence of nine words. So, eventually we’re going to have nine sets of features to represent these nine words, and index into the positions in the sequence, I’m going to use [latex]x^{<1>}[/latex], [latex]x^{<2>}[/latex], [latex]x^{<3>}[/latex] and so on up to [latex]x^{<9>}[/latex] to index into the different positions. use [latex]x^{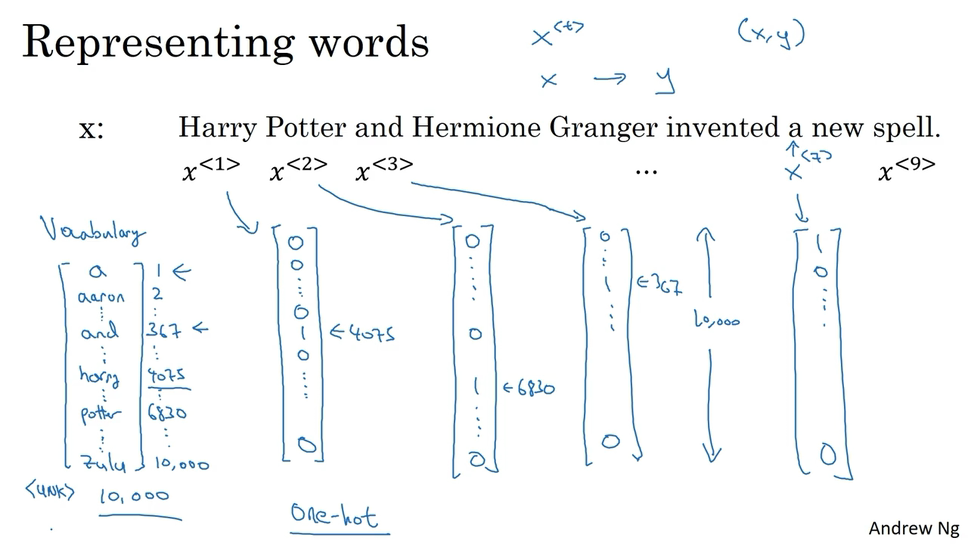 What if you encounter a word that is not in your vocabulary? Well the answer is, you create a new token or a new fake word called Unknown Word which under note as follows angle brackets UNK to represent words not in your vocabulary.
What if you encounter a word that is not in your vocabulary? Well the answer is, you create a new token or a new fake word called Unknown Word which under note as follows angle brackets UNK to represent words not in your vocabulary.
Recurrent Neural Network Model
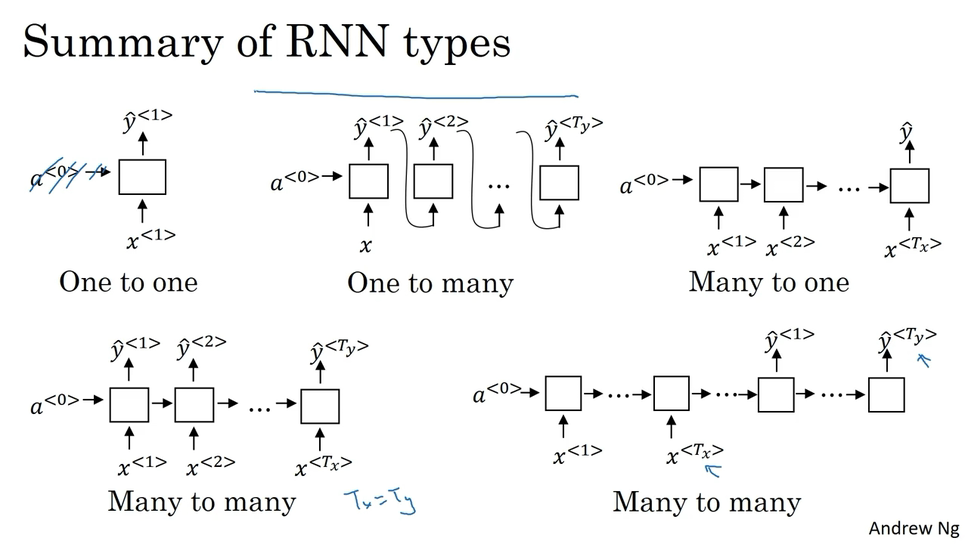
Why not a standard network? Problems:
- Inputs, outputs can be different lengths in different examples.
- Doesn’t share features learned across different positions of text.
And what a recurrent neural network does is when it then goes on to read the second word in a sentence, say X2, instead of just predicting Y2 using only X2, it also gets to input some information from what had computed that time-step one’s. At each time-step, the recurrent neural network passes on this activation to the next time-step for it to use. Now one limitation of this particular neural network structure is that the prediction at a certain time uses inputs or uses information from the inputs earlier in the sequence but not information later in the sequence. We will address this in a later video where we talk about a bidirectional recurrent neural networks or BRNNs. The activation function used in to compute the activations will often be a tanh and the choice of an RNN and sometimes, Relu are also used although the tanh is actually a pretty common choice. Simplified RNN notation : [latex]\begin{matrix} a^{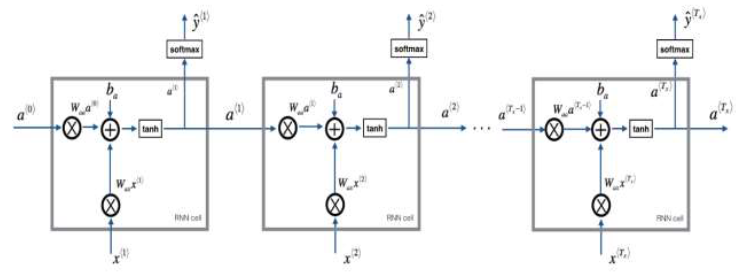
Backpropagation through time
As usual, when you implement this in one of the programming frameworks, often, the programming framework will automatically take care of backpropagation. Element-wise loss funtion : [latex]L^{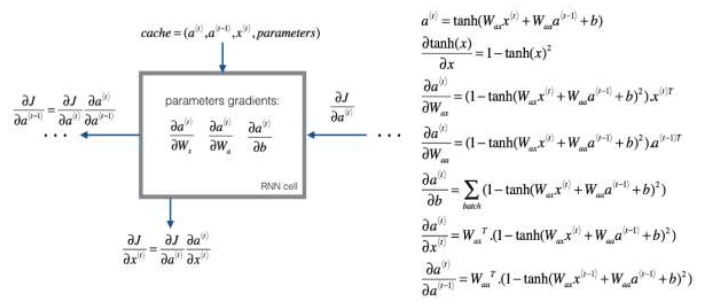
Different types of RNNs
Language model and sequence generation
What a language model does is given any sentence its job is to tell you what is the probability of a sentence, of that particular sentence. And this is a fundamental component for both speech recognition systems as you’ve just seen, as well as for machine translation systems where translation systems wants output. How do you build a language model?
- first need a training set comprising a large corpus of English text. Or text from whatever language you want to build a language model of. And the word corpus is an NLP terminology that just means a large body or a very large set of English text of English sentences.
- The first thing you would do is tokenize this sentence. And that means you would form a vocabulary as we saw in an earlier video. And then map each of these words to, say, one-hot vectors, all to indices in your vocabulary.
- One thing you might also want to do is model when sentences end. So another common thing to do is to add an extra token called a EOS.
- Go on to built the RNN model
- what [latex]a^{<1>}[/latex] does is it will make a softmax prediction to try to figure out what is the probability of the first words y. And so that’s going to be y<1>. So what this step does is really, it has a softmax it’s trying to predict. What is the probability of any word in the dictionary?
- Then, the RNN steps forward to the next step and has some activation, [latex]a^{<1>}[/latex] to the next step. And at this step, this job is try to figure out, what is the second word?
- whatever this given, everything that comes before, and hopefully it will predict that there’s a high chance of it, EOS end sentence token.
Sampling novel sequences
After you train a sequence model, one of the ways you can informally get a sense of what is learned is to have a sample novel sequences.
- what you want to do is first sample what is the first word you want your model to generate.
- …
Then you will generate a randomly chosen sentence from your RNN language model.
- words level RNN
- character level RNN
- advantage : you don’t ever have to worry about unknown word tokens.
- disadvantage : you end up with much more, much longer sequences.
- so they are not in widespread used today. Except for maybe specialized applications where you might need to deal with unknown words or other vocabulary words a lot.
Vanishing gradients with RNNs
It turns out the basics RNN we’ve seen so far it’s not very good at capturing very long-term dependencies.
- It turns out that vanishing gradients tends to be the bigger problem with training RNNs,
- although when exploding gradients happens, it can be catastrophic because the exponentially large gradients can cause your parameters to become so large that your neural network parameters get really messed up. So it turns out that exploding gradients are easier to spot because the parameters just blow up and you might often see NaNs, or not a numbers, meaning results of a numerical overflow in your neural network computation.
- And if you do see exploding gradients, one solution to that is apply gradient clipping. And what that really means, all that means is look at your gradient vectors, and if it is bigger than some threshold, re-scale some of your gradient vector so that is not too big. So there are clips according to some maximum value. So if you see exploding gradients, if your derivatives do explode or you see NaNs, just apply gradient clipping, and that’s a relatively robust solution that will take care of exploding gradients.
Gated Recurrent Unit(GRU)
The Gated Recurrent Unit which is a modification to the RNN hidden layer that makes it much better capturing long range connections and helps a lot with the vanishing gradient problems. 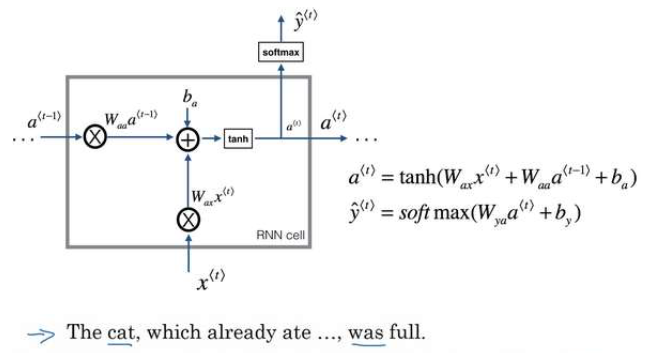 The GRU unit is going to have a new variable called c which stands for cell, for memory cell. And what the memory cell do is it will provide a bit of memory to remember. [latex]\tilde{c} ^{
The GRU unit is going to have a new variable called c which stands for cell, for memory cell. And what the memory cell do is it will provide a bit of memory to remember. [latex]\tilde{c} ^{
LSTM(long short term memory)unit
the long short term memory units, and this is even more powerful than the GRU. 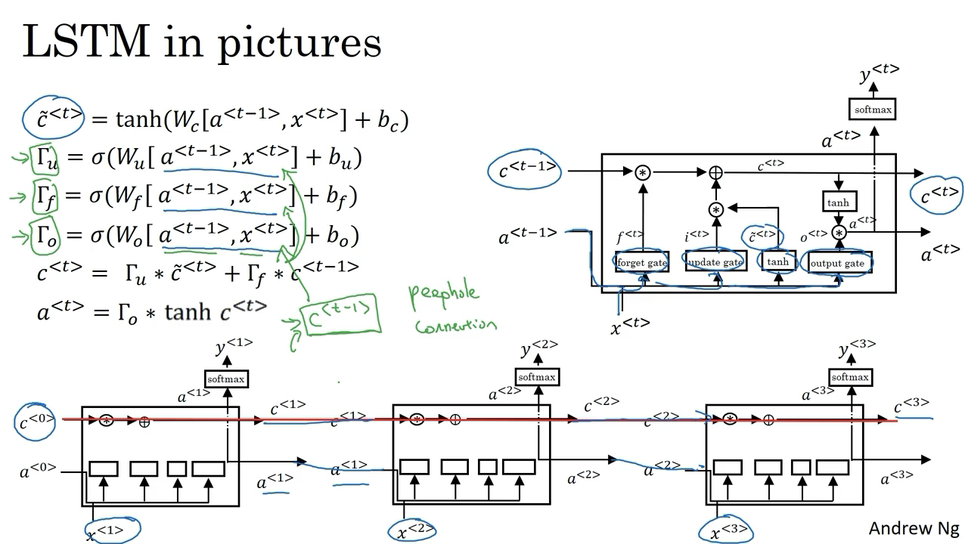 Perhaps, the most common one is that instead of just having the gate values be dependent only on a^{
Perhaps, the most common one is that instead of just having the gate values be dependent only on a^{
GRU
- relatively recent invention
- a simpler model and so it is actually easier to build a much bigger network, it only has two gates, so computationally, it runs a bit faster. So, it scales the building somewhat bigger models
LSTM
- actually came much earlier
- more powerful and more flexible since it has three gates instead of two.
LSTM has been the historically more proven choice.
Bidirectional RNN
Bidirectional RNNs, which lets you at a point in time to take information from both earlier and later in the sequence. In fact, for a lots of NLP problems, for a lot of text with natural language processing problems, a bidirectional RNN with a LSTM appears to be commonly used. The disadvantage of the bidirectional RNN is that you do need the entire sequence of data before you can make predictions anywhere.
Deep RNNs
The different versions of RNNs you’ve seen so far will already work quite well by themselves. But for learning very complex functions sometimes it’s useful to stack multiple layers of RNNs together to build even deeper versions of these models. For RNNs, having three layers is already quite a lot. Because of the temporal dimension, these networks can already get quite big even if you have just a small handful of layers. And you don’t usually see these stacked up to be like 100 layers. One thing you do see sometimes is that you have recurrent layers that are stacked on top of each other. But then you might take the output here, let’s get rid of this, and then just have a bunch of deep layers that are not connected horizontally but have a deep network here that then finally predicts y<1>.