Word Representation
NLP, Natural Language Processing Word embeddings, which is a way of representing words. that let your algorithms automatically understand analogies like that, man is to woman, as king is to queen, and many other examples.  Representing words using a vocabulary of words.
Representing words using a vocabulary of words.
One of the weaknesses of this representation is that it treats each word as a thing onto itself, and it doesn’t allow an algorithm to easily generalize the cross words.
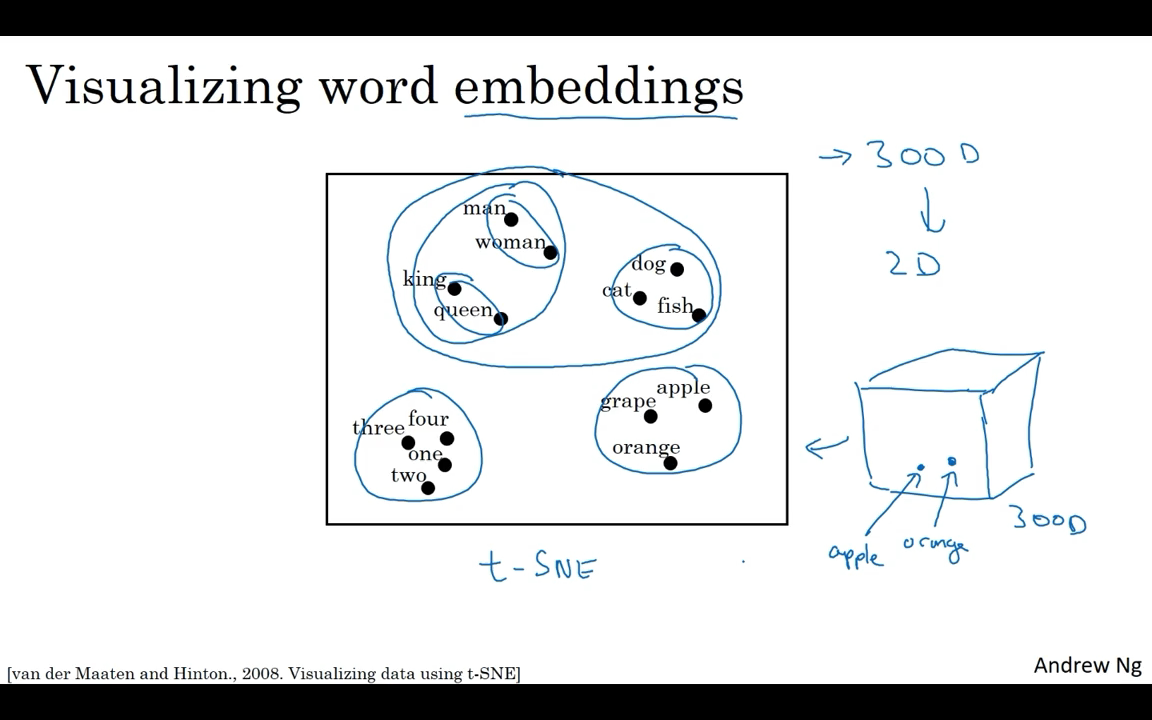 You see plots like these sometimes on the internet to visualize some of these 300 or higher dimensional embeddings. To visualize it, algorithms like t-SNE, map this to a much lower dimensional space.
You see plots like these sometimes on the internet to visualize some of these 300 or higher dimensional embeddings. To visualize it, algorithms like t-SNE, map this to a much lower dimensional space.
Using Word Embeddings
Transfer learning and word embeddings
- Learn word embeddings from large text corpus. (1-100B words or download pre-trained embedding online.)
- Transfer embedding to new task with smaller training set. (say, 100k words)
- Optional: Continue to finetune the word embeddings with new data.
Properties of Word Embeddings
One of the most fascinating properties of word embeddings is that they can also help with analogy reasoning. The most commonly used similarity function is called cosine similarity : [latex]CosineSimilarity(u,v) = \frac{u.v}{\left \ u \right \_2\left \ v \right \_2} = cos(\theta)[/latex]
Embedding Matrix
When you implement an algorithm to learn a word embedding, what you end up learning is an embedding matrix. And the columns of this matrix would be the different embeddings for the 10,000 different words you have in your vocabulary. 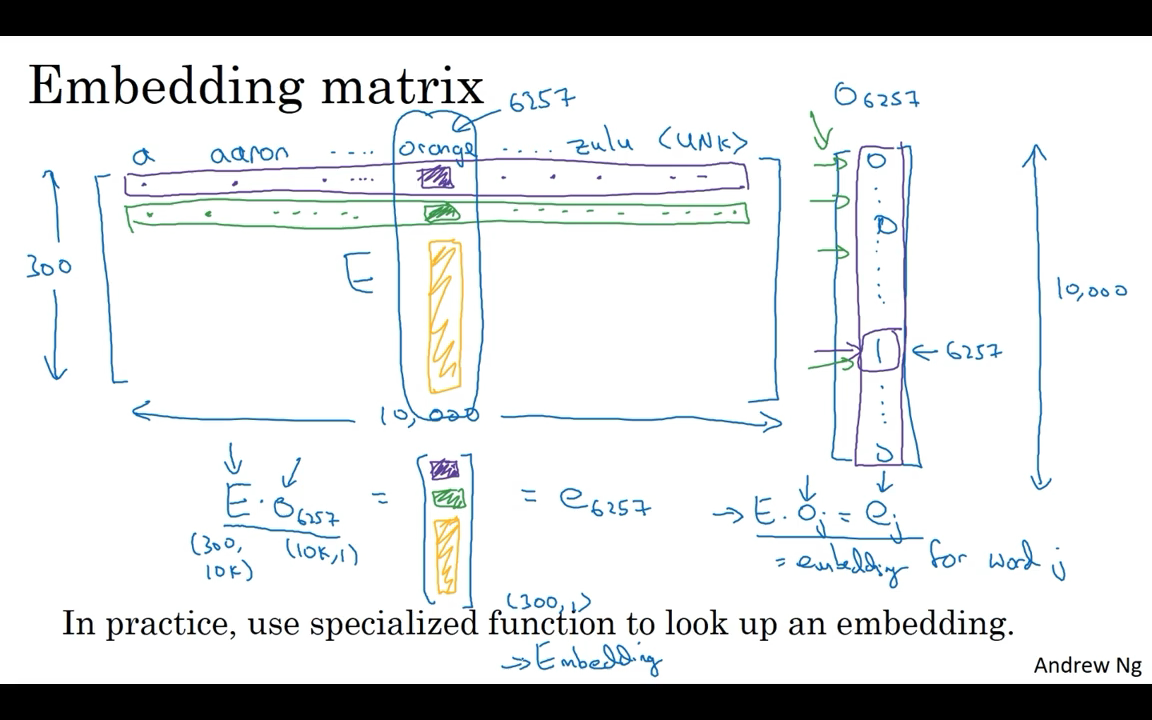
Learning Word Embeddings
It turns out that building a neural language model is a reasonable way to learn a set of embedding. Well, what’s actually more commonly done is to have a fixed historical window.
And using a fixed history, just means that you can deal with even arbitrarily long sentences because the input sizes are always fixed.
If your goal is to learn a embedding. Researchers have experimented with many different types of context.
- If your goal is to build a language model then it is natural for the context to be a few words right before the target word.
- But if your goal isn’t to learn the language model per se, then you can choose other contexts.
Word2Vec
The Word2Vec algorithm which is simple and computationally more efficient way to learn this types of embeddings.
Skip-Gram model
[latex]\begin{matrix} Softmax : & p(tc) = \frac{e^{\theta ^T_t e_c}}{\sum _{j=1}^{10,000} e^{\theta ^T_j e_c}} \\ Loss Function : & L(\hat y, y) = - \sum _{i=1}^{10,000} y_i log \hat y _i \end{matrix}[/latex] the primary problem is computational speed, because of the softmax step is very expensive to calculate because needing to sum over your entire vocabulary size into the denominator of the softmax.
a few solutions
- hierarchical softmax classifier
- negative sampling
CBow
the Continuous Bag-Of-Words Model, which takes the surrounding contexts from middle word, and and uses the surrounding words to try to predict the middle word.
Negative Sampling
What to do in this algorithm is create a new supervised learning problem. And the problem is, given a pair of words like orange and juice, we’re going to predict is this a context-target pair? It’s really to try to distinguish between these two types of distributions from which you might sample a pair of words. How do you choose the negative examples?
- sample the words in the middle, the candidate target words.
- use 1 over the vocab size, sample the negative examples uniformly at random, but that’s also very non-representative of the distribution of English words.
- the authors, Mikolov et al, reported that empirically, [latex]P(w_i) = \frac{f(w_i)^{\frac{3}{4}}}{\sum _{j=1}^{10,000}f(w_j)^{\frac{3}{4}}}[/latex]
GloVe Word Vectors
GloVe stands for global vectors for word representation. Sampling pairs of words, context and target words, by picking two words that appear in close proximity to each other in our text corpus. So, what the GloVe algorithm does is, it starts off just by making that explicit. 
Sentiment Classification
Sentiment classification is the task of looking at a piece of text and telling if someone likes or dislikes the thing they’re talking about. 
Debiasing Word Embeddings
Machine learning and AI algorithms are increasingly trusted to help with, or to make, extremely important decisions. And so we like to make sure that as much as possible that they’re free of undesirable forms of bias, such as gender bias, ethnicity bias and so on.
- So the first thing we’re going to do is identify the direction corresponding to a particular bias we want to reduce or eliminate.
- the next step is a neutralization step. So for every word that’s not definitional, project it to get rid of bias.
- And then the final step is called equalization in which you might have pairs of words such as grandmother and grandfather, or girl and boy, where you want the only difference in their embedding to be the gender.
- And then, finally, the number of pairs you want to equalize, that’s actually also relatively small, and is, at least for the gender example, it is quite feasible to hand-pick.