Object localization
Object detection is one of the areas of computer vision that’s just exploding. Object localization which means not only do you have to label this as say a car, but the algorithm also is responsible for putting a bounding box, so that’s called the classification with localization problem. Defining the target label y :
- pedestrian
- card
- motorcycle
- background
Need to output bx, by, bh, bw, class label(1-4) [latex]y=\begin{bmatrix} p_c \\ b_x \\ b_y \\ b_h \\ h_w \\ c_1 \\ c_2 \\ c_3 \end{bmatrix}[/latex]
If using squared error, then loss function : [latex]L(\hat y, y) = (\hat y_1 - y_1)^2 + (\hat y_2 - y_2)^2 + \cdots (\hat y_8 - y_8)^2[/latex] In practice you could use you improbably use a log likelihood loss for the [latex]c_1[/latex], [latex]c_2[/latex], [latex]c_3[/latex]to the softmax, output one of those elements, usually you can use squared error or something like squared error for the bounding box coordinates and then for [latex]p_c[/latex], you could use something like the logistic regression loss, although even if you use squared error or predict work okay.
Landmark detection
Neural network just output x and y coordinates of important points in image sometimes called landmarks that you want the netural network to recognize. The labels have to be consistent across different images.
Object detection
Sliding windows detection algorithm :
- using a pretty large stride in this example just to make the animation go faster
- repeat it, but now use a larger window
- then slide the window over again using some stride and so on, and you run that throughout your entire image until you get to the end
There’s a huge disadvantage of sliding windows detection which is the computational cost :
- if you use a very coarse stride, a very big stride, a very big step size, then that will reduce the number of windows you need to pass through the ConvNet, but that coarser granularity may hurt performance
- whereas if you use a very fine granularity or a very small stride, then the huge number of all these little regions you’re passing through the ConvNet means that there’s a very high computational cost
So before the rise of neural networks, people used to use much simpler classifiers
Convolutional implementation of sliding windows
Turn fully connected layers in your neural network into convolutional layers It turns out a lot of this computation done by these 4 ConvNet is highly duplicated Sliding windows convolutionally makes the whole thing much more efficient, but it still has one weakness which is the position of the bounding boxes is not going to be too accurate.
Bounding box predictions
A good way to get this output more accurate bounding boxes is with the YOLO algorithm, YOLO stands for you only look once. The basic idea is you’re going to take the image classification and localization algorithm and what the YOLO algorithm does is it takes the midpoint of each of the two objects and it assigns the object to the grid cell containing the midpoint. The advantage of this algorithm is that the neural network outputs precise bounding boxes as follows so long as you don’t have more than one object in each grid cell this algorithm should work okay. Assign an object to grid cell is you look at the mid point of an object and then you assign that object to whichever one grid cell contains the mid point of the object. This is a pretty efficient algorithm and in fact one nice thing about the YOLO algorithm which which accounts for popularity is because this is a convolutional implementation it actually runs very fast so this works even for real-time object detection. The YOLO paper is one of the harder papers to read. It’s not that uncommon sadly for even you know senior researchers to read research papers and have a hard time figuring out the details and have to look at the open source code or contact the authors or something else to figure out the details of these algorithms.
Intersection over union
Intersection over union, and just we use both for evaluating your object detection algorithm. So, what the intersection over union function does or IoU does is it computes the intersection over union of these two bounding boxes. So, the union of these two bounding boxes is this area, is really the area that is contained in either bounding boxes, whereas the intersection is this smaller region here. So, what the intersection over union does is it computes the size of the intersection, And by convention, law of computer vision task will judge that your answer is correct, if the IoU is greater than or 0.5 (just a human-chosen convention, there’s no particularly deep theoretical reason for it).
Non-max suppression
One of the problems of object detection as you’ve learned about so far is that your algorithm may find multiple detections of the same object so rather than detecting an object just once it might detect it multiple times non-max suppression is a way for you to make sure that your algorithm detects each object only once.
- so concretely what it does is it first looks at the probabilities associated with each of these detections count on the p_c, and then it first takes the largest one
- and says that’s my most confident detection
- so let’s highlight it,
- and all the ones with a high overlap with a high IoU with this one that you’ve just output will get suppressed.
- and find the one with the highest probability the highest
Non max means that you’re going to output your maximal probabilities classifications but suppress it close by ones that are non maximal so that’s as a name non max suppression.
Anchor Boxes
One of the problems with object detection as you’ve seen it so far is that each of the grid cells can detect only one object What if a grid cell wants to detect multiple objects here’s what you can do you can use the idea of anchor boxes. 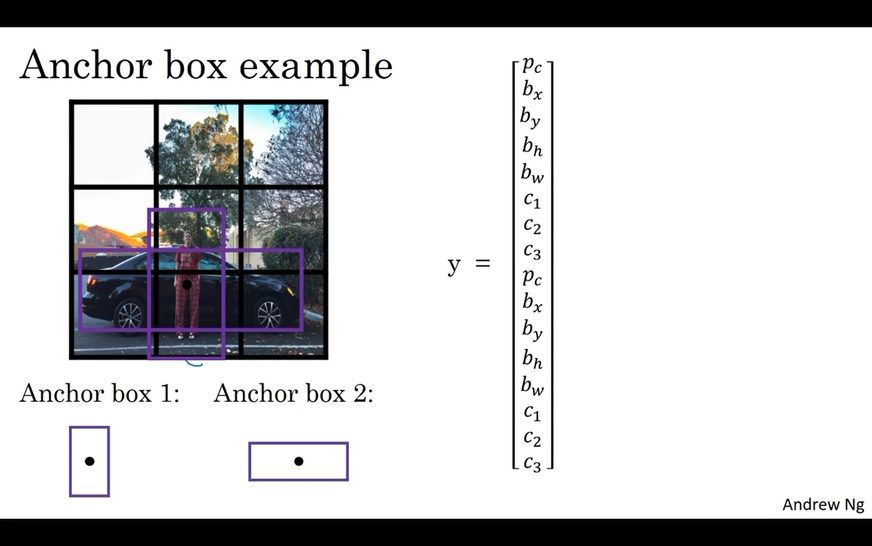 The idea of anchor boxes what you’re going to do is predefined two different shapes called anchor boxes or anchor boxes shapes and what you’re going to do is now be able to associate two predictions with the two anchor boxes and in general you might use more anchor boxes maybe five or even more. Anchor box algorithm :
The idea of anchor boxes what you’re going to do is predefined two different shapes called anchor boxes or anchor boxes shapes and what you’re going to do is now be able to associate two predictions with the two anchor boxes and in general you might use more anchor boxes maybe five or even more. Anchor box algorithm :
- Previously :
Echo object in training image is assigned to grid cell that contains that object’s midpoint.
- With two anchor boxes :
Echo object in training image is assigned to grid cell that contains object’s midpoint and anchor box for the grid cell with highest IoU.
Now just some additional details what if you have two anchor boxes but 3 objects in the same grid cell that’s one case that this algorithm doesn’t handle it well. Anchor boxes gives you is it allows your learning algorithm to specialize better in particular if your data set has some tall skinny objects like pedestrians and some wide objects like cars then this allows your learning algorithm to specialize. How to choose the anchor boxes :
- People used to just choose them by hand you choose maybe five or ten anchor box shapes that spans a variety of shapes that see to cover the types of objects you seem to detect.
- One of the later YOLO research papers is to use a k-means algorithm to group together two types of object shapes you tend to get and if we use that to select a set of anchor boxes that this most stereotypically representative of the may be multiple there may be dozens of object classes you’re trying to detect but that’s a more advanced way to automatically choose the anchor boxes.
Putting it together: YOLO algorithm

One of the most effective object detection algorithms that
also encompasses many of the best ideas across the entire computer vision literature that relate to object detection.
Region proposals (Optional)
Algorithm convolutionally but one downside that the algorithm is it just classifies a lot of regions where there’s clearly no object. Faster algorithms :
- R-CNN : Propose regions. Classify proposed regions one at a time. Output label + bounding box.
- Fast R-CNN : Propose regions. Use convolution implementation of sliding windows to classify all the proposed regions.
- Faster R-CNN : Use convolutional network to propose regions.
Although the faster R-CNN algorithm most implementations are usually still quite a bit slower than the YOLO algorithm. The idea of region proposals has been quite influential in computer vision.